

در دنیای دیجیتال امروز، از دست رفتن دادهها و توقف سرویسها میتواند برای کسبوکارها خسارتهای جبرانناپذیری به همراه داشته باشد. سرویس Disaster Recovery (DR)، توانایی بازگرداندن سرویس و دادهها در یک سایت یا ریجن مستقل پس از وقوع فاجعه است و با مفاهیمی مانند High Availability (HA)، Backup یا CDN تفاوت بنیادین دارد. پیادهسازی صحیح DR نه تنها تداوم کسبوکار را تضمین میکند ، بلکه ریسکهای مالی، اعتباری و عملیاتی ناشی از قطعیهای طولانیمدت را کاهش میدهد. در این مقاله، همراه با کلود دات آیآر، شما را با اصول، کاربردها، ریسکها و مفاهیم کلیدی RPO و RTO آشنا خواهیم کرد تا درک دقیق و عملی از سرویس DR و اهمیت آن در کسبوکارهای امروزی پیدا کنید.
سرویس DR در یک نگاه
سرویس Disaster Recovery (DR) مجموعهای از فرآیندها، معماریها و اتوماسیونهاست که به کسبوکارها اجازه میدهد پس از وقوع فاجعه در سایت اصلی، سرویسها و دادههای خود را به سرعت و با کمترین میزان از دست رفتن اطلاعات در یک سایت یا ریجن مستقل بازیابی کنند. DR فراتر از Backup و High Availability است و شامل مواردی مانند RPO و RTO، اجرای Runbook های خودکار، تستهای دورهای و برگشتپذیری سرویسها میشود. هدف اصلی DR تضمین تداوم عملیاتی و کاهش ریسک ناشی از حوادث غیرمنتظره مانند آتشسوزی دیتاسنتر، قطع برق سراسری، از کار افتادن شبکه، تحریمهای قانونی، جنگ، زلزله یا بلایای طبیعی است.
- بازگرداندن سریع سرویسها: توانایی بازیابی اپلیکیشنها، دیتابیسها و فایلها در کوتاهترین زمان ممکن پس از فاجعه.
- حفظ دادههای حیاتی: اطمینان از حداقل از دست رفتن داده با توجه به RPO تعیینشده.
- تداوم کسبوکار: جلوگیری از توقف عملیات اصلی سازمان و کاهش ریسک مالی و اعتباری.
- آمادگی برای سناریوهای فاجعه: پوشش رویدادهایی مانند خرابی دیتاسنتر، آتشسوزی، قطع شبکه یا تحریم قانونی.
- تست و اعتبارسنجی دورهای: اجرای Failover و Restore در محیطهای آزمایشی برای اطمینان از عملکرد واقعی DR.
- اتوماتیکسازی فرآیندها: استفاده از Runbookها و ابزارهای Orchestration برای کاهش خطای انسانی و سرعت بخشیدن به بازیابی.
مطالب پیشنهادی: راهنمای خرید سرور ابری مجازی
کاربرد سرویس DR
سرویس Disaster Recovery (DR) نه تنها تضمین میکند که کسبوکارها پس از فاجعههای بزرگ قادر به ادامه فعالیت باشند، بلکه به مدیران فناوری اطلاعات امکان میدهد تا در هر سناریوی بحرانی، تصمیمات سریع و هوشمندانه بگیرند. کاربردهای DR گسترده و متنوع هستند و بسته به نوع سازمان و حساسیت دادهها، میتوانند شامل بازیابی کامل سرویسها، حفاظت از دادههای حیاتی، کاهش ریسک مالی و بهبود مستمر فرآیندها باشند. در ادامه، مهمترین کاربردهای سرویس DR را بررسی میکنیم.
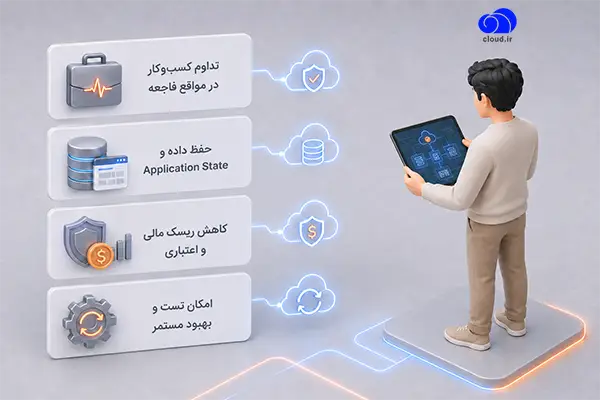
تداوم کسبوکار در مواقع فاجعه
در سناریوهای بحرانی که کل سایت یا دیتاسنتر اصلی از کار میافتد، سرویس DR تضمین میکند که کسبوکار بتواند فعالیتهای حیاتی خود را بدون وقفه ادامه دهد. این سناریوها میتوانند شامل موارد زیر باشند:
- آتشسوزی دیتاسنتر: از بین رفتن سرورها، شبکه و تجهیزات ذخیرهسازی در یک محل فیزیکی.
- قطع برق سراسری یا مشکلات زیرساخت شبکه: عدم دسترسی به سرویسها و دادهها در سطح شهر یا منطقه.
- تحریمها یا محدودیتهای قانونی (Legal Shutdown): مسدود شدن دسترسی به منابع فناوری اطلاعات به دلایل حقوقی یا سیاسی.
در همه این موارد، وجود یک معماری DR معتبر و اتوماسیون مناسب، زمان Downtime را به حداقل میرساند و عملیات کسبوکار را حفظ میکند.
حفظ داده و Application State
یکی دیگر از کاربردهای حیاتی DR، اطمینان از حفظ دادهها و وضعیت اجرای سیستمها در زمان بحران است. این یعنی علاوه بر اطلاعات بنیادین، وضعیت لحظهای سرویسها نیز تا حد امکان قابل بازیابی باشد.
در عمل، سرویس DR میتواند:
- دادههای اصلی مانند دیتابیسها و فایلهای مهم را بازیابی کند بهطوری که کمترین میزان از دست رفتن اطلاعات رخ دهد.
- برخی اطلاعات موقتی سرویسها را تا حد امکان حفظ یا دوباره ایجاد کند؛ مثل اطلاعات ورود کاربران (Session) یا دادههای موقتی که در عملکرد نرمافزار استفاده میشوند.
- با استفاده از نسخههای پشتیبان (Snapshot) و کپیبرداری لحظهای (Replication)، امکان بازگشت به آخرین وضعیت پایدار سیستم را فراهم کند.
این قابلیتها تضمین میکنند که نهتنها دادهها حفظ شوند، بلکه کاربران و سیستمها نیز بتوانند پس از بازیابی، بدون اختلال و با حداقل وقفه به فعالیت خود ادامه دهند.
کاهش ریسک مالی و اعتباری
از دست رفتن سرویس یا داده میتواند به سرعت به خسارت مالی و آسیب به اعتبار سازمان منجر شود. با اجرای DR، میتوان هزینههای downtime و اثر آن بر SLA و مشتریان را کاهش داد. برای مثال:
- یک سازمان با RTO = 4 ساعت و RPO = 15 دقیقه میتواند در صورت قطعی، تنها ۱۵ دقیقه از دادهها را از دست بدهد و سرویس خود را ظرف ۴ ساعت بهطور کامل بازگرداند.
- کاهش زمان downtime باعث افزایش اعتماد مشتریان و کاهش جریمههای قراردادی میشود.
- محاسبه تأثیر مالی ناشی از قطعیها (Cost of Downtime) به تصمیمگیری درباره سرمایهگذاری در DR کمک میکند.
امکان تست و بهبود مستمر
یکی دیگر از کاربردهای کلیدی DR، فراهم کردن امکان تست و بهبود مستمر است. بدون آزمون دورهای و بررسی فرآیندهای failover و failback، هیچ DR واقعی پیادهسازی نشده است. این بخش شامل موارد زیر است:
- اجرای Runbookها برای شبیهسازی سناریوهای فاجعه و بررسی صحت فرآیندهای بازیابی.
- تستهای دورهای Failover و Failback برای تضمین برگشتپذیری سرویسها.
- بازخورد از نتایج تستها برای بهبود معماری، اتوماسیون و SLA.
این فرآیند باعث میشود سرویس DR همواره آماده و قابل اعتماد باقی بماند و ریسک خطاهای انسانی کاهش یابد.
مطالب پیشنهادی: CDN ویدئو چیست و چگونه کار میکند؟
ریسک های استفاده نکردن از سرویس DR
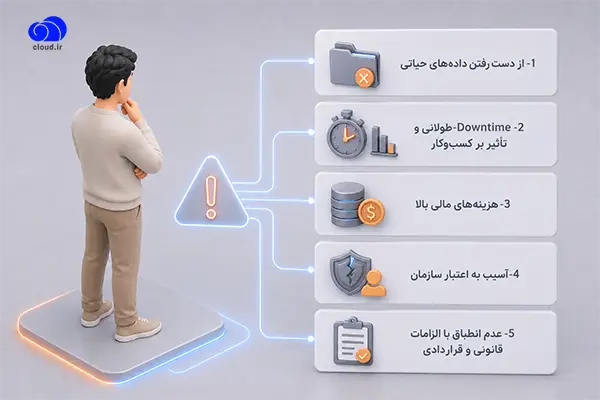
عدم استفاده از سرویس Disaster Recovery میتواند پیامدهای جبرانناپذیری برای کسبوکارها داشته باشد. حتی اگر سازمان زیرساختهای HA یا Backup داشته باشد، بدون DR واقعی در مواجهه با فاجعههای سطح سایت یا ریجن، امکان بازیابی سریع و کامل وجود ندارد. ریسکهای کلیدی شامل موارد زیر هستند:
- از دست رفتن دادههای حیاتی: بدون تعریف RPO، هرگونه خرابی میتواند منجر به از بین رفتن اطلاعات مهم شود.
- Downtime طولانی و تأثیر بر کسبوکار: قطعی سرویسها میتواند باعث توقف تولید، فروش یا ارائه خدمات شود.
- هزینههای مالی بالا: هر ساعت توقف سرویس میتواند هزینه مستقیم و غیرمستقیم قابل توجهی داشته باشد؛ این هزینهها شامل جریمههای SLA، کاهش فروش و خسارت به برند است.
- آسیب به اعتبار سازمان: مشتریان و شرکا به سرعت به کیفیت خدمات حساس میشوند و قطع مکرر یا طولانیمدت، اعتماد آنها را کاهش میدهد.
- عدم انطباق با الزامات قانونی و قراردادی: در برخی سازمانها، نداشتن برنامه مناسب برای بازیابی پس از بحران (DR) میتواند باعث شود سازمان نتواند به تعهدات قانونی یا مفاد قراردادهای خود در زمینه نگهداری و حفاظت از دادهها عمل کند
بهطور خلاصه، بدون DR واقعی، سازمانها صرفاً دارای سیستمهای Backup یا HA هستند و هیچ تضمینی برای بازگرداندن سرویسها در سناریوهای فاجعهآمیز وجود ندارد.
نحوه کار کردن این سرویس
سرویس DRaaS (Disaster Recovery as a Service) مجموعهای از فرآیندها، اتوماسیونها و معماریهاست که برای بازیابی سریع سرویسها و دادهها در شرایط فاجعه طراحی شده است. نحوه کار این سرویس شامل چند مرحله کلیدی و ابزارهای فنی است که با هم ترکیب میشوند:
- تعریف RPO و RTO: تعیین حداکثر داده قابل از دست رفتن و حداکثر زمان بازیابی سرویس. این مرحله پایه و اساس تمامی معماری DR است.
- طراحی سناریوهای Site-Level Disaster: شبیهسازی رویدادهایی مانند آتشسوزی دیتاسنتر، قطعی شبکه، از کار افتادن کامل یک Region یا شرایط بحرانی مانند جنگ انجام میشود.
- اتوماسیون و Runbookها: استفاده از ابزارهای orchestration برای اجرای خودکار فرآیندهای Failover و Failback و کاهش خطای انسانی.
- پیادهسازی الگوهای DR (DR Patterns):
- Backup & Restore: بازگرداندن داده و سرویس از نسخه پشتیبان.
- Pilot Light: راهاندازی نسخه کوچک از سرویس در سایت DR و آمادهسازی برای Failover سریع.
- Warm Standby: سیستم فعال با ظرفیت محدود که در زمان فاجعه به سرویس کامل ارتقا مییابد.
- Multi-Site Active-Active: تمام سایتها فعال و در هماهنگی کامل برای تداوم سرویس در هر سناریوی فاجعه.
- تست دورهای و اعتبارسنجی: اجرای Failover و Restore در محیط آزمایشی برای اطمینان از کارکرد واقعی DR و بهبود مداوم فرآیندها.
- Failback و برگشتپذیری: پس از رفع مشکل در سایت اصلی، بازیابی سرویسها و دادهها به موقعیت اصلی بدون اختلال برای کاربران.
این مراحل نشان میدهد که DR صرفاً یک Backup ساده یا Multi-Zone نیست؛ بلکه یک فرآیند کامل، اتوماتیک و با SLA مشخص است که میتواند تداوم کسبوکار و محافظت از دادهها را تضمین کند.
دو مفهوم کلیدی در DR: مفاهیم RPO و RTO
در سرویس Disaster Recovery (DR)، دو مفهوم کلیدی RPO و RTO تعیین میکنند که چه مقدار داده میتواند از دست برود و چه مدت طول میکشد تا سرویسها پس از فاجعه دوباره فعال شوند. این دو معیار اساس طراحی و عملکرد DR را تشکیل میدهند.
RPO چیست؟ (حداکثر داده قابل از دست رفتن)
- تعریف: RPO (Recovery Point Objective) حداکثر مقدار دادهای است که سازمان میتواند بدون آسیب جدی از دست بدهد.
- کاربرد عملی: اگر RPO = 24 ساعت باشد، Snapshot روزانه کافی است؛ اگر RPO = 5 دقیقه باشد، باید از replication بیدرنگ استفاده شود.
- اهمیت: تعیین RPO باعث انتخاب تکنولوژی مناسب برای Backup، Replication و طراحی DR میشود.
RTO چیست؟ (حداکثر زمان بازیابی)
- تعریف: RTO (Recovery Time Objective) حداکثر زمان مجاز برای بازیابی سرویسها پس از فاجعه است.
- کاربرد عملی: در سناریوی Failover به سایت DR، RTO مشخص میکند که سرویسها باید طی چه مدت در دسترس قرار گیرند.
- اهمیت: RTO معیار سنجش کارایی Runbook، اتوماسیون و SLA سرویس DR است.
ارتباط RPO و RTO با طراحی DRaaS
- RPO و RTO تعیین میکنند که کدام الگوهای DR (Backup & Restore, Pilot Light, Warm Standby, Multi-Site Active-Active) مناسب هستند.
- مشخص میکنند چه نوع replication، Multi-Region setup و SLA نیاز است.
- به مدیران IT امکان میدهد برای دادهها و سرویسهای حیاتی سطح اهمیت تعریف کنند و منابع را بهینه تخصیص دهند.

جمع بندی
سرویس Disaster Recovery (DR) فراتر از Backup یا High Availability است و تضمین میکند که کسبوکارها حتی در سناریوهای فاجعهآمیز بتوانند سرویسها و دادههای خود را با حداقل از دست رفتن اطلاعات و کمترین Downtime بازیابی کنند. با تعریف دقیق RPO و RTO، طراحی معماری Multi-Region، اجرای Runbookهای خودکار و تستهای دورهای، سازمانها قادر خواهند بود ریسک مالی، عملیاتی و اعتباری ناشی از قطعیهای طولانیمدت را به حداقل برسانند. انتخاب و پیادهسازی صحیح DR، تضمینکننده تداوم کسبوکار و محافظت واقعی از دادهها است، و همراهی با تیمهای متخصص مانند کلود دات آیآر میتواند فرآیند طراحی، پیادهسازی و بهبود مستمر DR را برای سازمانها ساده و امن سازد.



